
Reconstructing piecewise planar scenes with multi-view regularization
2019-02-27 10:36WeijieXiXuejinChen
Computational Visual Media 2019年4期
Weijie Xi, Xuejin Chen()
Abstract Reconstruction of man-made scenes from multi-view images is an important problem in computer vision and computer graphics. Observing that manmade scenes are usually composed of planar surfaces,we encode plane shape prior in reconstructing man-made scenes. Recent approaches for single-view reconstruction employ multi-branch neural networks to simultaneously segment planes and recover 3D plane parameters.However, the scale of available annotated data heavily limits the generalizability and accuracy of these supervised methods. In this paper, we propose multiview regularization to enhance the capability of piecewise planar reconstruction during the training phase, without demanding extra annotated data.Our multi-view regularization enables the consistency among multiple views by making the feature embedding more robust against view change and lighting variations.Thus, the neural network trained by multi-view regularization performs better on a wide range of views and lightings in the test phase. Based on more consistent prediction results, we merge the recovered models from multiple views to reconstruct scenes.Our approach achieves state-of-the-art reconstruction performance compared to previous approaches on the public ScanNet dataset.
Keywords scene modeling;multi-view;regularization;neural network
1 Introduction
Multi-view reconstruction has been extensively studied in computer graphics and computer vision for decades. Studying this problem can be beneficial for many practical applications, such as indoor navigation, augmented reality, and human—robot interaction. However, reconstruction of indoor scenes is non-trivial due to object clutters, occlusions, large variety of object appearances, etc.
Traditional multi-view reconstruction methods build dense correspondence between pixels and recover the 3D positions of points. Hand-crafted similarity metrics (e.g., normalized cross-correlation and semi-global matching [1, 2]) are employed to compute point-wise correspondences among multiple views. Without integrating contextual information or global geometric prior, these methods have trouble in reconstructing complete and comprise models for scenes with repetitive patterns or many textureless regions.
With the rapid development of deep learning techniques, many deep neural network-based (DNNbased) methods have been proposed [3—6]. These methods usually compute the pixel-wise plane-sweep cost volume [7] from multiple view images and use the 3D convolutional neural network (CNN) to infer the depth map directly. These methods work well on reconstructing an object where the images are taken under multiple views around the object. However,the computational cost of using 3D CNNs to infer depth map from cost volumes is huge.
Man-made scenes, especially indoor scenes, are usually composed of plane surfaces [8]. This shape prior provides more global geometric constraint for depth inference and helps on generating cleaner scene models. Recently, a series of deep learning-based methods have been proposed to reconstruct piece-wise planar scenes from image [9—12]. From a single RGB image, these methods simultaneously segment plane instances and estimate 3D plane parameters. The planarity hypothesis has been proven very effective in reconstructing man-made scenes [8, 13].
Although these deep learning methods have achieved promising success in single-view reconstruction,inadequate consideration of multi-view consistency and the deficiency of densely annotated training data lead to poor generalizability of the inference feature, especially when the viewpoint changes significantly. As a result, over-segmentation and under-segmentation often appear in the predicted plane instance, which gives rise to the wrong reconstruction of the 3D scene. One possible way to solve this problem is to increase the amount of training data. However, it is nontrivial to obtain accurate depth maps and plane annotations.
In this paper, we propose a multi-view regularization method which enhances existing single-view reconstruction networks for piecewise planar scenes to obtain more robust feature representation. Our multi-view regularization mainly works in the training phase. From multiple images of the same scene, we enforce the network to embed the inference features of the same plane instance under different views as the same as possible while the features of different plane instances are as different as possible. In the test phase, our method is similar to the existing singleview planar reconstruction network. Each single-view image is fed to the network to obtain an instance segmentation map of the plane and corresponding plane parameters to infer the scene depth map. Then the prediction results of multiple images are merged to compose the 3D scene, as shown in Fig. 1. Compared with the existing methods, our method does not bring additional calculation while improving network performance. During the training phase, there is no increase in the annotation amount of the training data.

Fig. 1 Given multiple images under different viewpoints, we reconstruct the scene by recovering plane segments and the depth map under the planar shape constraint for each image. Based on our multi-view regularization, the recovered planes and depths are more consistent and can be composed to reconstruct the scene more completely.
In summary, our contributions are the following:
·We propose multi-view regularization to enhance the feature extraction capability of existing single-view planar reconstruction networks,especially against to viewpoint changes and lighting variance.
·Our method does not require extra annotated training data and does not bring additional computational cost during the test phase.
·Our method achieves state-of-the-art planar reconstruction performance on the public dataset ScanNet [14].
2 Related work
Multi-view reconstruction. Conventional methods[1,2,15,16]adopt plane-sweep algorithm to construct matching confidence, then optimize the disparity of reference frustum from matching confidence.Although these methods show successful results under ideal Lambertian scenarios [3], they suffer from poor generalizability to common scenes. Incomplete and incorrect reconstruction usually occur due to low texture, object occlusion, or transparency. Recently,deep learning techniques widely success in image recognition and detection, and many deep learningbased methods [3—6] have been proposed for 3D reconstruction. These methods construct a pixel-wise cost volume according to extracted 2D features, then use 3D CNN to directly regress the disparity of reference frustum. While these methods achieve successful performance in object reconstruction benchmark[17,18],they are computationally expensive.
Planar scene modeling. For 3D plane modeling tasks, traditional methods extract 3D geometric cues and apply global geometric constraints in modeling process. Delage et al. [19] first extract line segments from the input image, and then use Markov Random Field (MRF) model to label superpixels according to the predefined plane classes. But this needs to be established under the assumption of the Manhattan world. Barinova et al. [20] first extract geometric primitives from an input 2D image, and then use the Conditional Random Field (CRF) model to label the extracted geometric primitives. Similarly,assumption that the scene is composed of flat ground and vertical walls should be made. Although these methods can effectively extract and model the plane in the scene, they all need strong prior assumptions which severely restricts the generalizability of the algorithm.
Learning-based methods.In the literature, a series of learning-based methods have been proposed for plane scene modeling. Early work[21]introduces a learning-based framework to infer the depth map from a single RGB image. With the improvement of deep learning technology, more and more methods based on Convolutional Neural Networks(CNNs)have been proposed. However, most of these techniques simply produce the scene depth map without extracting plane information such as plane instance and plane parameters.
Recently, several CNN-based methods have been proposed to extract 3D plane structure. Among them,PlaneNet[9]and Yang and Zhou[10]use the semantic segmentation framework to extract plane instances in the scene, and directly infer plane parameters by a CNN. The difference between them is the way of supervision of the plane parameters. PlaneNet [9]uses traditional plane fitting methods to generate annotations for plane parameters, while Yang and Zhou [10] translate the plane parameter prediction problem into plane depth prediction of the scene and use the ground truth depth values to supervise the plane parameters. However, a drawback of these methods is that only a fixed number of planes can be inferred each time because of the widely used semantic segmentation network architecture. This problem was later solved by PlaneRCNN [11] and Yu et al. [12]. Based on the framework of Mask-RCNN, PlaneRCNN [11] first detects the plane in the image and then performs instance segmentation on the detected mask. Yu et al. [12] address this problem by mean-shift clustering of the extracted feature maps to perform instance segmentation for the planes in the scene.
3 Methodology
Our multi-view regularization method is proposed to enhance piece-wise planar scene reconstruction from a single RGB image. Combining the recovered 3D planes from multiple images, we could obtain a more complete model for the scene. The network framework adopted by our method is the single-view plane modeling network [12] as the backbone for feature inference. We first quickly introduce the network architecture and then introduce our multiview regularization method. Figure 2 illustrates the framework of our proposed method.
3.1 Single-view planar modeling network
For the convenience of presentation,we denote SVPNet as the single-view plane network [12]. Taking a single color image as input,SVPNet infers a depth map from 3D plane recovery,and the blue block in Fig.2 shows the inference pipeline. It first exploits an encoder—decoder framework to extract features from the color image,then through three convolution layers to produce a 2-channel plane embedding feature map, pixel-wise plane parameters,and a binary semantic segmentation mask which indicate plane or not, respectively. The extracted plane embedding feature maps are clustered to obtain plane instance by a modified mean shift clustering algorithm. Concurrently, the scene depth map of plane regions is inferred from extracted plane parameters. Combining the instance-wise plane segmentation mask and inferred depth map, a piecewise 3D planar scene is modeled.
3.2 Multi-view regularization
The purpose of our multi-view regularization design is enforcing the consistency of plane feature embedding from different views against view change and lighting variance during the training phase. To enhance singleview planar scene modeling performance, we take multiple images under different views of the same scene as input for training. Among these images, one image is labeled with ground truth plane instance segmentation labelsS, plane parametersand scene depthD. The image with annotation we called reference imageIrand the otherKimages are called source-view images. All of these images are fed intoK+1 share weight sub-networks which include encoder—decoder block and embedding layer which to extract plane embedding featurefor each input color image.
To establish the pixel-wise correspondence between the reference image andKsource-view images,the embedding feature maps in the source-viewsare projected into the reference view according to their camera parameters and ground truth depth map. Therefore, we obtainK+ 1 projected embedding feature maps from theKsource views and reference view, denote asIn order to formulate the multi-view regularization term, the discriminative loss function is extended from Ref.[22]to multi-view feature maps. The singleview discriminative loss function is defined as

where the variance termLvarpulls each embedding to the mean embedding of the corresponding plane instance, and the distance termLdistpushes the embedding centers of each plane instances away from each other. The definition of them are
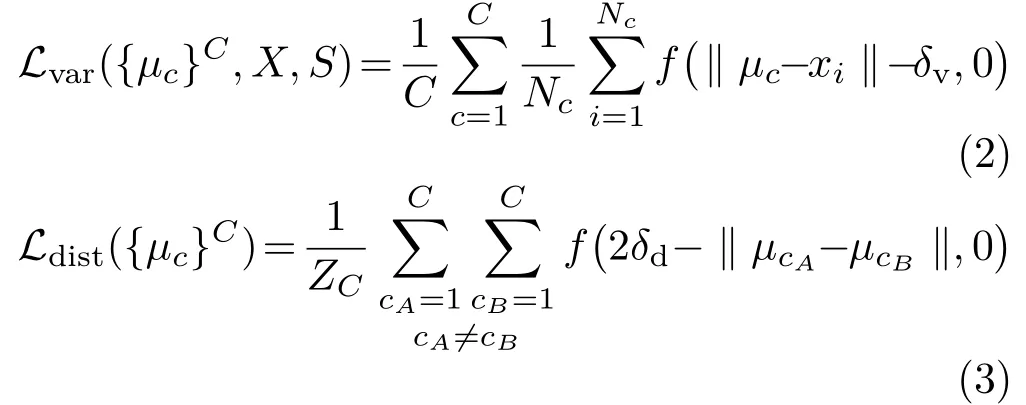
whereZC=C(C -1) is a normalization constant acting as the average of the push distance between different plane instances,f(x)=max(x,0),Cis the number of the ground truth plane instances,Ncis the number of pixels in the plane clusterc,μcis the mean embedding of the plane clusterc, and{μc}Cis the overall set of mean embedding,xiis theithembedding vector on plane clustercof the embedding featureX,‖ · ‖is the L2 distance term,δvandδdare the two margins forLvarandLdistrespectively.
The single-view loss is used to constrain the compactness of the embedding space, while our multi-view regularization term tends to enforce the consistency of the embedding vectors of the same plane instance under different views. For each sourceview image, we get the projected embedding feature mapand the corresponding plane instance labelSrwhich is the annotation under reference view image.Combining these projected embedding feature maps with the embedding feature map of the reference view,we denote the asFor each plane instance that can be extracted fromSr, we compute the multi-view regularization term.Specifically, we calculate the mean embeddingμcof all the pixels in each plane instance among all theK+1 embedding feature maps{Fk}K+1. With the shared mean embeddingμcamong allK+1 views,our multi-view regularization term is given by

Since the ultimate goal is to recover the plane instances and their geometry, we combine the semantic segmentation lossLs, plane parameter lossLnwhich are defined in Ref. [12] with our multi-view regularization termLmvto train our designed model.Therefore, the overall loss function of the network is written as

All these loss function terms are differentiable, so the entire network can be trained in an end-to-end manner.
4 Experiments
We first evaluate our multi-view regularization term on the task of single view reconstruction both quantitatively and qualitatively. Then we show a series of reconstruction results by merging the inferred geometry from multiple views. We implement our method with PyTorch [23]. We use SGD optimizer[24] with a learning rate of 10-4and a weight decay of 10-5, and the batch size is set to 16.
We construct the dataset for training and test based on the ScanNet [14]. Following previous single-view piecewise planar scene modeling works [9, 12], we first construct a dataset containing 48,214 reference images for training. For each reference image,the ground truth annotation with plane instance segmentation map and plane parameters are obtained by fitting planes on the reconstructed mesh in the scenes of ScanNet. To train the network with the multi-view regularization,we select two images which are 20 frames before and after each reference image in the image sequence with corresponding camera intrinsic and extrinsic parameters. At the test phase of single view reconstruction, the trained network takes only one color image as input. For fairness, we evaluate our model on the test set which consists of 760 images, the same as Refs. [9, 12].
4.1 Quantitative evaluation
We first compare our model with the baseline model SVPNet [12]. We evaluate the planar scene modeling performance with the per-plane recall and per-pixel recall metrics which are the percentage of correct prediction of the planes and pixels,respectively. The predicted plane is considered a correct prediction when plane instance segmentation intersection-over-union (IOU) score with the ground truth segmentation map is larger than 0.5 and the mean difference between the inferred depth and ground truth depth map is less than a thresholdσd,which ranges from 0.05 to 0.6 m. The experimental comparison results are shown in Table 1. We can see that our model achieves better planar scene modeling performance than the baseline model,especially when the depth threshold is small. Considering that our method does not bring any additional network parameters and computational cost compared to the baseline model at the test phase, we can conclude that the proposed multi-view regularization improves the capability of the single-view inference network.
Furthermore, we compare our method with PlaneRCNN [11], PlaneNet [9], and NYU-Toolbox[25]. Figure 3 shows the comparison results the test set. Our method achieves the best performance among these methods, which ulteriorly demonstrates the effectiveness of our method.
4.2 Qualitative evaluation

Fig. 3 Comparison between the enhanced SVPNet by our multi-view regularization term and three existing methods for single-view planar scene reconstruction on the ScanNet test set.

Table 1 Per-pixel and per-plane recalls on the ScanNet test dataset compared with the baseline SVPNet [12]

Fig. 4 Comparison between the single-view reconstruction results of our method and the baseline SVPNet [12]. (a) Input images. (b) The plane clustering results by SVPNet and (c) our method. (d) The inferred depth map by SVPNet and (e) our method. (f, g) Two novel views of the recovered models using SVPNet and (h, i) our method.
Figure 4 shows a group of results of plane instance segmentation, depth estimation, and reconstructed models using our method and the baseline model[12] on the ScanNet dataset [14]. Comparing (b)and (c) in Fig. 4, we can observe that our method enhances the ability of the network of detecting and recovering small plane instances and improves the model robustness to avoid over-segmentation of entire plane into multiple pieces. From Figs. 4(d)—4(i), we conclude that our method also enhances the ability of the network to recover correct 3D plane parameters because the three branches of the network share the same feature extractor and they can be mutually improved by joint training.
4.3 Multiple view consistency evaluation
The goal we designed the multi-view regularization is to enhance the feature consistency of multiple views, thereby improving the robustness of the network against view change and lighting variance.We validate the multi-view consistency of our method from two perspectives: plane segmentation consistency and 3D planar model correctness.
Plane segmentation consistency. We randomly select three images from different views in the same scene and test our enhanced single-view reconstruction network on each image independently.Figure 5 displays the plane instance segmentation results obtained by our method and three stateof-the-art approaches [9, 11, 12]. It shows that our method achieves the best result in maintaining the segmentation consistency among different views.Compared with the existing methods, our method can effectively reduce over-segmentation and undersegmentation as highlighted by the orange boxes.Moreover, the plane boundaries generated by our methods are more clear and consistent.
Geometry correctness. For the task of modeling piecewise planar scenes, the ultimate goal is to get a complete and correct 3D model of the scene. Given multiple images taken under different views in the same scene, we first run our enhanced network to reconstruct the plane instances for each image. Then we transform the reconstructed mesh from each image to the reference view according to their associated camera parameters and merge the meshes to obtain a more complete reconstruction result of the scene.Figure 6 shows the reconstructed results of two scenes using our method and the baseline model [12]. For each scene, we select three frames under adjacent viewpoints for reconstruction. Generally, our method reconstructs more view-consistent results. In the first scene, the red book flys away in the reconstructed model using SVPNet because it is segmented to the wall region by mistake. The desktop area is stretched a lot using SVPNet [12]. In comparison, the shape of the desktop is well recovered and consist among different views. In the second scene, the wall region reconstructed from different views using our method is much more consistent than that reconstructed using SVPNet [12]. These examples illustrate that our multi-view regularization can enhance the robustness of the single-view reconstruction network against view change and lighting variation, and therefore a more accurate 3D scene model can be obtained.

Fig. 5 Comparison of the plane segmentation results of multiple images under different views using our method and other approaches.

Fig. 6 The reconstruction results of two scenes from multiple images using our method and SVPNet [12].
5 Conclusions
In this paper, we propose a novel method to enhance a single-view reconstruction network by multi-view regularization for modeling piecewise 3D planar scenes. Our method enforces the consistency of the embedding features during the training phase,thereby enhances the robustness of the network against view change and lighting variation. Our method achieves state-of-the-art performance on the task of indoor scene reconstruction on the public ScanNet dataset. We believe that our proposed multiview regularization can be flexibly integrated with many single-view inference networks without bringing extra computational cost.
Acknowledgements
This work was supported by the National Key R&D Program of China under Grant 2017YFB1002202,the National Natural Science Foundation of China(NSFC) under Grant 61632006, as well as the Fundamental Research Funds for the Central Universities under Grants WK3490000003 and WK2100100030.
Open AccessThis article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format,as long as you give appropriate credit to the original author(s)and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use,you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095.To submit a manuscript, please go to https://www.editorialmanager.com/cvmj.
 Computational Visual Media2019年4期
Computational Visual Media2019年4期
- Computational Visual Media的其它文章
- Practical BRDF reconstruction using reliable geometric regions from multi-view stereo
- Evaluation of modified adaptive k-means segmentation algorithm
- Mixed reality based respiratory liver tumor puncture navigation
- InSocialNet: Interactive visual analytics for role–event videos
- Adaptive deep residual network for single image super-resolution
- A three-stage real-time detector for traffic signs in large panoramas