
A Trust Evaluation Mechanism Based on Autoencoder Clustering Algorithm for Edge Device Access of IoT
2024-03-13 13:19XiaoFengandZhengYuan
Computers Materials&Continua 2024年2期
Xiao Feng and Zheng Yuan
1Cyber Security Academy,Beijing University of Posts and Telecommunications,Beijing,100876,China
2Department of Cyberspace Security,Beijing Electronic Science and Technology Institute,Beijing,100070,China
3State Grid Info-Telecom Great Power Science and Technology Co.,Ltd.,Beijing,102211,China
ABSTRACT First,we propose a cross-domain authentication architecture based on trust evaluation mechanism,including registration,certificate issuance,and cross-domain authentication processes.A direct trust evaluation mechanism based on the time decay factor is proposed,taking into account the influence of historical interaction records.We weight the time attenuation factor to each historical interaction record for updating and got the new historical record data.We refer to the beta distribution to enhance the flexibility and adaptability of the direct trust assessment model to better capture time trends in the historical record.Then we propose an autoencoder-based trust clustering algorithm.We perform feature extraction based on autoencoders.Kullback leibler(KL)divergence is used to calculate the reconstruction error.When constructing a convolutional autoencoder,we introduce convolutional neural networks to improve training efficiency and introduce sparse constraints into the hidden layer of the autoencoder.The sparse penalty term in the loss function measures the difference through the KL divergence.Trust clustering is performed based on the density based spatial clustering of applications with noise(DBSCAN)clustering algorithm.During the clustering process,edge nodes have a variety of trustworthy attribute characteristics.We assign different attribute weights according to the relative importance of each attribute in the clustering process,and a larger weight means that the attribute occupies a greater weight in the calculation of distance.Finally,we introduced adaptive weights to calculate comprehensive trust evaluation.Simulation experiments prove that our trust evaluation mechanism has excellent reliability and accuracy.
KEYWORDS Cross-domain authentication;trust evaluation;autoencoder
1 Introduction
The concept of the Internet of Things (IoT) has affected all walks of life in society.However,there are many issues in terms of security and user privacy during the implementation of the concept.In the field of Internet of Things,cloud computing is an important research direction.It is crucial to design a credible trust evaluation mechanism to ensure the reliability of data [1].The traditional cloud computing model often results in high latency because computing and data storage are centralized in remote data centers,which makes real-time response requirements unmet for applications such as intelligent transportation or industrial automation [2].Second,this model can cause network congestion problems,as many devices attempt to upload and download data simultaneously,leading to packet loss and decreased network performance[3].In addition,with the flow of data during transmission and storage,privacy and security concerns cannot be ignored [4].Finally,cloud computing models often require a lot of data center resources[5],but these resources are not always fully utilized,especially for lightweight computing tasks,and this highly resource-intensive model can be wasteful.
Edge computing can greatly improve the shortcomings of traditional cloud computing.Allocate computing and data processing tasks to edge devices to reduce network latency.This has been widely used in smart cities[6].Processing data through edge devices reduces the computing pressure on the cloud.thereby reducing the risk of network collapse and improving network security [7].But there are also many potentials and challenges in the current edge computing research field.For example,computing resources limit edge computing task processing performance.The dynamic nature of the device environment also adds to the complexity of edge computing task processing[8].
The low detection rate of trust evaluation mechanisms is one of the challenges facing the edge computing research field.There may be dynamically adaptive malicious nodes in the network.They will evade detection by pretending to be honest nodes or accumulating trust value in a short period.Therefore,a trust mechanism that can dynamically monitor node changes is crucial to ensuring the reliability of edge computing systems[9].
How to improve task allocation and processing efficiency is also a major challenge in the current research field.When computing resources are limited,factors such as network status and device performance need to be considered when processing large-scale computing tasks.Therefore,intelligent algorithms with excellent performance are needed to assist in improving computing efficiency[10].
In conclusion,edge computing is a powerful tool for addressing the needs of the IOT era,but to fully leverage its benefits,issues,and challenges such as trust assessment and task processing efficiency must be addressed.To address the above challenges,this study proposes a novel crossdomain authentication architecture,which is built based on a trust evaluation mechanism.The research contributions of this authentication architecture are as follows:
1) We introduce a credible cross-domain authentication process,encompassing registration,certificate issuance,and cross-domain authentication procedures to ensure secure interactions among devices in different domains.A direct trust evaluation mechanism based on the time decay factor is proposed,taking into account the influence of historical interaction records.We weighted the time attenuation factor to each historical interaction record for updating and got the new historical record data.We refer to the beta distribution to enhance the flexibility and adaptability of the direct trust assessment model to better capture time trends in the historical record.
2) We propose an autoencoder-based trust clustering algorithm.Feature extraction is based on autoencoders.KL divergence is used to calculate the reconstruction error.When constructing a convolutional autoencoder,we introduce convolutional neural networks to improve training efficiency and introduce sparse constraints into the hidden layer of the autoencoder.The sparse penalty term in the loss function measures the difference through the KL divergence.
3)Trust clustering is performed based on the density based spatial clustering of applications with noise (DBSCAN) clustering algorithm.During the clustering process,edge nodes have a variety of trustworthy attribute characteristics.We assign different attribute weights according to the relative importance of each attribute in the clustering process,and a larger weight means that the attribute occupies a greater weight in the calculation of distance.
4)We combine the adaptive weight calculation method to obtain a comprehensive trust evaluation score.Simulation experiments prove that the trust evaluation mechanism proposed in this article has excellent performance in terms of reliability and accuracy.
The structure of this article is as follows.In Section 2,we present research on edge computing and trust assessment.In Section 3,we propose a cross-domain authentication framework based on trust evaluation mechanism.In Section 4,we describe a trust evaluation algorithm based on autoencoder clustering.In Section 5,we carry out simulation experiment analysis.In section 6,we summarize.
2 Related Work
Trust assessment plays a key role in the edge computing research field.Xu et al.[11]proposed an innovative trust evaluation model,which is based on risk and feedback.The research of Guo et al.[12]focused on security in an edge computing environment.Ensure that each node is trusted and that only authorized nodes can join the execution environment.The authentication method is used to verify the identity of the node.The work of Chi et al.[13] analyzed the trust domains between different devices and entities,which are composed of devices that trust each other.The establishment and management of this relationship are essential to ensure legitimacy and credibility.Din et al.[14]proposed that through the establishment of trust relationships and the use of social trust networks,the communication reliability between nodes in the cell network has been significantly improved.
Kuang et al.[15]studied how to reasonably allocate tasks to devices and nodes when storage and computing resources are limited.Jo?ilo et al[16]optimized task processing time through the efficient allocation of unlimited resources to unnamed devices.Dynamically obtain edge computing resources through devices to improve resource utilization and reduce overall network latency.Valerio et al.[17]aimed to solve the problem of virtual machine allocation in edge computing.The model considers energy consumption,load,and other factors,and adopts the Markov decision method to achieve the goal of minimizing delay.Ouyang et al.[18,19]proposed a UAV mission offloading trust scheme based on two key indicators,namely energy consumption and service reliability.
Multi-access edge computing (MEC) [20,21] mainly studies how to perform low-latency data retrieval.However,edge server storage resources are limited.CSEdge solves the trust problem in storage based on blockchain.It also solves the incentive problem and allocates storage space based on reputation value.Assessing credibility through consensus algorithms provides a solution for edge storage[22].BEoT[23]combines edge computing and blockchain.There are application scenarios in many fields.Smart contracts and identity authentication are applied to improve the security of the architecture.
Vehicle edge computing utilizes vehicles(VEC)[24]to reduce application latency by using vehicles to migrate computing tasks.Prices are calculated based on the two-stage Stackelberg game model.The VEC server serves as the leader and the vehicle serves as the follower.Through deep reinforcement learning,a management strategy for non-shared computing needs is designed to maximize the profits of both parties [25].Cviti? et al.designed a classification model based on logit boost [26].A classification model with high accuracy is trained through multiple traffic characteristics of IoT devices.Li et al.proposed a multi-level power grid model that focused on analyzing the vulnerability of components[27].
3 Cross-Domain Authentication Architecture Based on Trust Evaluation Mechanism
In edge computing network systems,changes in edge nodes will increase network instability.Based on this problem,we propose an authentication architecture based on a trust evaluation mechanism and blockchain.
We summarized the main symbols in Table 1.

Table 1:Symbol specification
3.1 Cross-Domain Authentication Architecture
At present,the field of edge computing is becoming increasingly mature and diversified,and a variety of computing architectures have been developed for various application scenarios.This provides a solid foundation for realizing more efficient resource collaborative utilization and application sharing.The trusted authentication architecture based on trust evaluation is shown in Fig.1.
A good edge computing trust model should be able to cope with most malicious attack modes.The existing trust model has insufficient ability to identify and prevent,and there are shortcomings in security management.It is unable to deal with complex attack methods such as swing attacks and collusion attacks.So that malicious nodes can still hide in the network after malicious attacks.
3.2 Cross-Domain Authentication Process
To ensure the accuracy of the study and facilitate reference,we summarized the main symbols in Table 1.

Figure 1:Cross-domain authentication architecture
3.2.1 Registration Process
First,the edge server generates identity tagsLAi,public and private keys,(PKi,PVi)and timestampsTifor the nodenj.This information marks the uniqueness of the node’s identity.All information is encrypted and stored on the blockchain,accessible only to edge servers.Then the edge server sends a messageRequestito the blockchain node to apply for a registered node.
After receivingRequestithe blockchain node performs signature verification to ensure that the source is legitimate and has not been tampered with.If the digital signature passes,the registration information will be written to the blockchain.The registration is successful.
3.2.2 Certificate Issuance Process
The certificate issuance process is a key step for nodes in the same domain to apply for certificatesCAfrom edge servers.This process serves as the basis for trust establishment and identity authentication in edge computing environments.The edge server first queries the identity information and public key(LAj,PKj)of the certificate-issuing node through the blockchain.This information is key for subsequent verification and communication.Then send the node informationIito the blockchain node together.
If the information is correct,the blockchain server generates a numberNUMiand certificate informationCAiand sends them to the application node.The certificate is successfully issued.The certificate information is shown below:
3.2.3 Cross-Domain Authentication Process
Assume that the source node of the domainAneeds to establish communication with the destination node of domainB.First,the domainAedge server needs to query the domainBedge server’s public keyPKBand labelLABthrough the blockchain and generate identity informationMessage.i.Then niusePKBencryptionMessage.Ato generate a request messageRequestAand send it tonB.
After the edge server of the domainBreceives the request messageRequestA,the server first decryptsRequestAthrough the private keyPVBto obtain the identity informationMessage.A.Then query the public keyPKiof the source node nAand the public keyPKAof the server.The server of the domainBwill perform verification,and if all verifications pass,subsequent services will be provided.Failure to authenticate will result in a denial of service.
3.3 Direct Trust Evaluation Mechanism
Direct trust is an important concept that can be measured.In the network,we can quantify the task execution performance of nodes to define and calculate trust.present nodenjtrust value at a timet.
Suppose that the task during the interaction between nodeniand nodenjin timetis represented as a set of time series probability data:
However,it is important to note that the effectiveness of interactive recording diminishes over time.This is because early cooperative behavior may no longer reflect the current state of trust.We add weights to reduce the impact of time.This factor takes into account the temporal impact of historical interaction records,ensuring that time is taken into account when assessing direct trust.The definition is as follows:
whereεiis the time attenuation factor oftitime,we weighted the time attenuation factor to each historical interaction record for updating,and got the new historical record data:
The Beta distribution has flexible capabilities,and we refer to the beta distribution to enhance the flexibility and adaptability of the direct trust assessment model to better capture time trends in the historical record.
whereαis regulator of direct trust value,represents the sum of success records.
4 Trust Evaluation Mechanism Based on Autoencoder Clustering
In this paper,indirect trust assessment is based on a distributed trust establishment approach.Firstly,the intermediate trust assessment module collects trust feedback information from various nodes in the entire network.The value of these feedback pieces of information is significant as they reflect the trustworthiness exhibited by the assessed nodes when interacting with other nodes.Evaluating nodes gather these feedback inputs from multiple nodes and consolidate them into an overall trust assessment.This consolidation process employs a trust aggregation algorithm.The flow chart of trust assessment is shown in Fig.2.
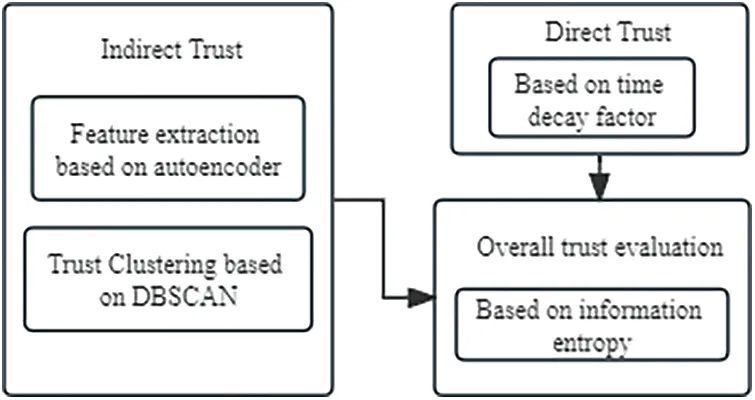
Figure 2:Trust assessment flow chart
This dynamic information is expressed in the form of,which clearly shows the growth of the trust value of the nodeni,and provides the nodes in the network with the latest information about the behavior of the node being evaluated.This dynamic trust-building process helps nodes in the network better adapt to changing trust needs and environmental conditions.
Assume that there are m evaluation nodes in the middle layer,and the set of nodes isE={e1,e2,...,em}.For evaluation nodeei,interacts with all device nodes.As the number of interactions increases,it means that the more frequently two parties interact,the greater the likelihood of trust.So we set weights for the evaluation nodes:
The indirect trust value is expressed as:
Evaluating whether a node is trustworthy is crucial to the evaluation of indirect trust.If the recommendation node takes malicious actions for personal gain,such as delivering false reports to the trust evaluation node,then this will seriously interfere with the final trust evaluation of the target node.
4.1 Feature Extraction Based on Convolutional Autoencoder
Firstly,we introduce an autoencoder for feature extraction.The autoencoder first is the input layer,where the user evaluation data is encoded as a high-dimensional feature vector.This is followed by the hidden layer,which is responsible for feature extraction,and the output layer,which is responsible for decoding the feature vectors to reconstruct the data.Autoencoders measure the efficiency of feature extraction by comparing pre-encoding and post-decoding feature vectors.This is achieved by calculating the reconstruction error.In node clustering,KL divergence is usually used to calculate the reconstruction error.KL divergence is a measure used to measure the difference between two probability distributions.The lower KL divergence indicates that the similarity between the two distributions is higher,that is,the feature extraction effect is better.KL divergence is calculated as follows:
wheregiandhirepresent the input and output feature vectors,respectively.
When constructing a convolutional autoencoder,we introduce convolutional neural networks to improve training efficiency.It is an effective regularization technique to introduce sparse constraints into the hidden layer of the autoencoder.By leaving most neurons inactive,the complexity of the network is reduced and overfitting is prevented.This helps the model to better generalize to previously unseen data.By calculating the mean activation of each hidden neuronavgj,we can learn which neurons are active and which are inactive.The sparse penalty term in the loss function measures the difference through the KL divergence.This allows the network to learn from fewer activated neurons,thereby reducing the risk of overfitting.
The loss function is expressed as:
where?is the sparse penalty coefficient andKLimeasures similarity based on KL divergence.
Once the encoder is trained,the value of the loss function is relatively small,indicating that the encoder has learned an effective feature representation.Then we can use the encoder to extract the features.
4.2 Trust Clustering Based on DBSCAN
In this section,the DBSCAN algorithm is introduced based on auto-encoder feature extraction.DBSCAN organizes data by the density of sample points and performs clustering according to the density of data points.The algorithm first defines the concept of neighborhood.DBSCAN defines the neighborhood of each data point through the neighborhood radius,that is,the distanceθfrom the point is considered as the neighborhood.
DBSCAN defines a core point as a point that contains at leastMinPtssample points in the neighborhood.That is,if the number of nodes in the neighborhood of the node x is greater thanMinpts,then x is the core point.Assuming a core pointx1,if the neighborhoodx1containsx2,then thex1density is directx2.DBSCAN uses the core point as the starting point to gather the points with direct density into the same cluster,thus achieving data clustering operations.
During the clustering process,edge nodes have a variety of trustworthy attribute characteristics.We assign different attribute weights according to the relative importance of each attribute in the clustering process,and a larger weight means that the attribute occupies a greater weight in the calculation of distance.Assuming a total ofMattributes of edge nodes,the neighborhood distanceNDof any noderand nodesis calculated as follows:

Then we describe the clustering process.First,we randomly select a node as the starting point and calculate the number of neighbor nodes.If the number of neighbor nodes is greater thanMinPts,The node’s neighbor nodes are added to the node cluster.The neighborhood expansion of the newly added points is continued to ensure that all reachable core points are added to the cluster.If the neighborhood of a core point contains other core points,they will be connected to the same cluster.All data points that are not assigned to the cluster are labeled as noise points.These points do not belong to any cluster.Repeat the above process until all data points have been accessed and classified.We end up with one or more clusters,each containing a set of data points dense with each other,while the noise points do not belong to any cluster.The specific algorithm flow is shown in Algorithm 1.

4.3 Overall Trust Evaluation
In this section,we comprehensively consider direct and indirect trust evaluation values to calculate the final overall trust.However,determining the relative importance of these two trust parameters is a key challenge.To solve this problem,we adopt an approach based on information entropy to determine their weights more objectively.The information entropy is calculated as follows:
The weight is calculated as follows:
Then the overall trust evaluation value is:
The overall calculation process is shown in Algorithm 2.
5 Simulation and Analysis
This section verifies the effectiveness of the proposed trust model and trust evaluation mechanism based on autoencoder clustering(TEE)through simulation experiments.
5.1 Analysis of the Trust Evaluation Model
In this section,we simulate and test the performance of the credit model.We analyzed model performance at different node sizes.According to the actual network conditions,most nodes are trusted nodes,so we set the number of malicious nodes to 30%.We use two key metrics to evaluate the effectiveness of the authentication architecture based on trust assessment.Based on the average response time(RT)and malicious detection recall rate(Recall)to assist in evaluating the performance of the model.
RT reflects the system’s ability to quickly adapt to changes and is very important for performance evaluation in IoT edge computing environments.In the experiment,we use different trust computing mechanisms,including DME(Distributed reputation management),RMD(Robust multidimensional trust mechanism),ART(A reliable trust mechanism),and the proposed TEE mechanism.By comparing the RTS of these mechanisms,we can verify which mechanism has faster computation speed and thus better ADAPTS to changes in the network environment.As shown in Fig.3,TEE,ART,and DME mechanisms are significantly more capable of detecting malicious nodes than RMD mechanisms.This shows that the TEE mechanism is not only excellent in terms of computational efficiency,but also very powerful in detecting malicious behavior.According to the experimental results,the proposed TEE mechanism is significantly superior to ART,RMD,and DME mechanisms in Recall.TEE performs better in Recall as the number of devices increases.

Figure 3:The value of Recall and RT varies with the number of devices
5.2 Analysis of Trusted Clustering Algorithm Based on Autoencoder
In our study,we found that the AEDC algorithm performs well in clustering tasks with different weight configurations.As illustrated in Fig.4,under lower weights,such as 0.3 and 0.4,the AEDC algorithm exhibits superior performance compared to K-MEANS.This can be partially attributed to the adaptability of the AEDC algorithm,which enables it to better accommodate the characteristics of the data under varying weight settings.It excels in recognizing different features within the data,allowing it to capture subtle differences more effectively under lower-weight conditions,thus enhancing clustering accuracy.This adaptability is of paramount importance in numerous application domains,particularly in cases where the emphasis on different features may evolve,such as in recommendation systems.
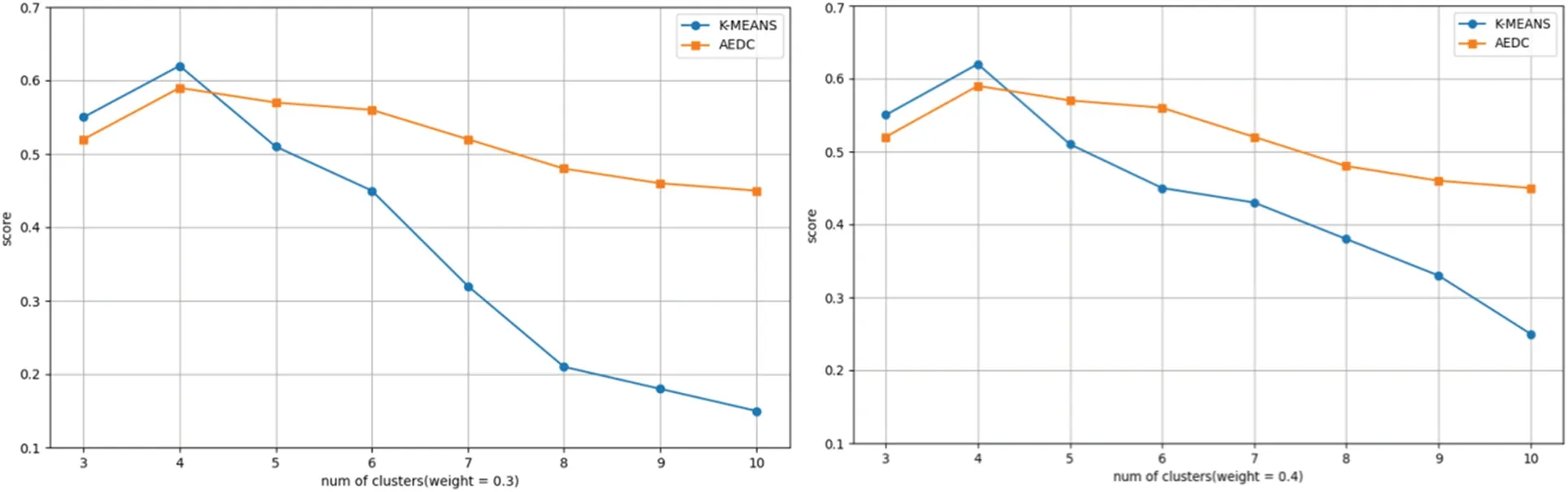
Figure 4:The score of K-MEANS and AEDC varies with the number of clusters at weights equal to 0.3 and 0.4
Furthermore,we investigated the impact of different weight settings on the performance of the AEDC algorithm and the K-MEANS algorithm.Our research demonstrates the stability of AEDC algorithm performance under higher weight values and its lower sensitivity to data features.As illustrated in Fig.5,with the weights gradually increased from 0.3 to 0.6,we observed a convergence in the performance of both algorithms.This implies that the AEDC algorithm maintains outstanding performance in high-weight environments,with minimal interference from variations in data features.This is particularly exciting,as it suggests that the AEDC algorithm can consistently deliver exceptional performance across various application scenarios.
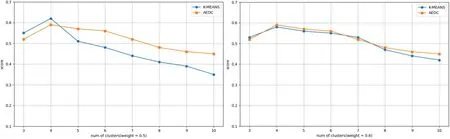
Figure 5:The score of K-MEANS and AEDC varies with the number of clusters at weights equal to 0.5 and 0.6
This phenomenon of gradual convergence in performance offers increased flexibility in algorithm selection for real-world applications.It allows us to choose suitable algorithms flexibly based on specific weight setting requirements without concerns about performance degradation.This has significant practical value in data mining tasks and cluster analysis,as the characteristics and demands of data may evolve continuously in practical applications.
6 Conclusion
In conclusion,this study introduces an innovative trust evaluation mechanism for accessing IoT edge devices,significantly enhancing system performance by integrating key elements such as crossdomain authentication,trust clustering,and adaptive weight considerations.Firstly,we successfully introduce a blockchain-based cross-domain authentication process,ensuring secure interoperability among devices in different domains,thereby enhancing system reliability.Secondly,we design a trust clustering algorithm based on autoencoder,improving trust assessment accuracy by comprehensively considering data,and effectively supporting system reliability and accuracy.Lastly,we introduce an adaptive weight calculation method,further enhancing system performance by comprehensively considering various factors affecting trust assessment.The evaluation mechanism provided in this article can be applied to actual IoT scenarios.Especially scenarios involving several elements such as the Internet of Things,blockchain,and trust assessment.Its limitation is that the blockchain limits the overall efficiency of the network and increases the network’s operating costs.How to improve the processing efficiency of network tasks while ensuring high network reliability is a challenge.
Acknowledgement:Not applicable.
Funding Statement:This work is supported by the 2022 National Key Research and Development Plan“Security Protection Technology for Critical Information Infrastructure of Distribution Network”(2022YFB3105100).
Author Contributions:The authors confirm contribution to the paper as follows:study conception and design:Xiao Feng,Zheng Yuan;data collection:Zheng Yuan;analysis and interpretation of results:Xiao Feng,Zheng Yuan;draft manuscript preparation:Zheng Yuan.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials:Data not available due to legal restrictions.Due to the nature of this research,participants of this study did not agree for their data to be shared publicly,so supporting data is not available.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computers Materials&Continua2024年2期
Computers Materials&Continua2024年2期
- Computers Materials&Continua的其它文章
- ASLP-DL—A Novel Approach Employing Lightweight Deep Learning Framework for Optimizing Accident Severity Level Prediction
- A Normalizing Flow-Based Bidirectional Mapping Residual Network for Unsupervised Defect Detection
- Improved Data Stream Clustering Method:Incorporating KD-Tree for Typicality and Eccentricity-Based Approach
- MCWOA Scheduler:Modified Chimp-Whale Optimization Algorithm for Task Scheduling in Cloud Computing
- A Review of the Application of Artificial Intelligence in Orthopedic Diseases
- IR-YOLO:Real-Time Infrared Vehicle and Pedestrian Detection