
TransTM: A device-free method based on time-streaming multiscale transformer for human activity recognition
2024-03-20 06:44YiLiuWeiqingHungShngJingBoiZhoShuiWngSiyeWngYnfngZhng
Defence Technology 2024年2期
Yi Liu , Weiqing Hung , Shng Jing , Boi Zho , Shui Wng , Siye Wng *,Ynfng Zhng
a Institute of Information Engineering Chinese Academy of Sciences, School of Cyber Security, University of Chinese Academy of Sciences, Beijing, China
b School of Information Management, Beijing Information Science and Technology University, Beijing, China
Keywords:Human activity recognition RFID Transformer
ABSTRACT RFID-based human activity recognition (HAR) attracts attention due to its convenience, noninvasiveness, and privacy protection.Existing RFID-based HAR methods use modeling, CNN, or LSTM to extract features effectively.Still, they have shortcomings: 1) requiring complex hand-crafted data cleaning processes and 2)only addressing single-person activity recognition based on specific RF signals.To solve these problems, this paper proposes a novel device-free method based on Time-streaming Multiscale Transformer called TransTM.This model leverages the Transformer's powerful data fitting capabilities to take raw RFID RSSI data as input without pre-processing.Concretely, we propose a multiscale convolutional hybrid Transformer to capture behavioral features that recognizes singlehuman activities and human-to-human interactions.Compared with existing CNN- and LSTM-based methods, the Transformer-based method has more data fitting power, generalization, and scalability.Furthermore,using RF signals,our method achieves an excellent classification effect on human behaviorbased classification tasks.Experimental results on the actual RFID datasets show that this model achieves a high average recognition accuracy (99.1%).The dataset we collected for detecting RFID-based indoor human activities will be published.
1.Introduction
Human activity recognition (HAR) aims to recognize specific actions of people based on sensor data.For its wide usage in human surveillance and assistance[1-10],it has gained significant interest from academia and industry.Advances in radio frequency identification (RFID) based HAR [11] have attracted numerous research curiosity due to the nature of contact-free and infringing-free.As we know, when a person moves within the communication range of the deployed RFID tag and reader, the backscattered signal will be reflected and diffracted, resulting in a unique mapping of the signal fluctuations.Thus, RFID enables unobtrusive HAR recognition, as shown in Fig.1.
Researchers have done a series of works in RFID-based HAR.Early method [12] manually extracted features, resulting in fewer representative features.More fine-grained features are automatically extracted with the development of deep learning.Wang et al.used a convolutional neural network (CNN) to design a classification model.However, convolution operations are challenging to process time-domain information, so they cannot accurately analyze the relative positional relationship between human limbs and torso over a period of time [13].To accurately recognize the time sequence of human activities,neural networks need to extract spatiotemporal features from the input data.Thereby [14,15]designed the model utilizing long-short-term memory (LSTM),which is memorable and time-sensitive.However,LSTM needs help in training, such as a large footprint, slow convergence, and overfitting.Contrastively, Transformer can capture long-distance information and dynamically adjust the receptive field according to the content for its self-attention mechanism, thus outperforming LSTM.Therefore,Transformer is recognized as HAR’s most suitable model for feature extraction.

Fig.1.Overall flow chart of the experiment.The antenna acquires data and produces signal features.Then the features are processed by the model and transformed into probability vectors.
However, shortcomings of existing RFID-based HAR research impede practical applications.Specifically, 1): Well-designed approaches[13-15]hardly handle data from various distributions,as their approaches highly rely on hand-crafted data cleaning methods before the data enters deep learning-based classification models,as shown in Tables 1 and 2):These methods are difficult to deal with the complex HAR in real life because they only solve the single-human activities recognition based on a specific RF signal.Therefore, a method that does not require hand-crafted data cleaning and can recognize single-human activity and HHI based on multiple RF signals requires further study, enabling low-cost identification and privacy protection.
In this paper, we propose a novel Time-streaming Multiscale Transformer (TransTM) model, which is an end-to-end trainable neural network to exploit the advantages of deep learning techniques for device-free based HAR tasks.Our model inputs the raw RFID Signal Strength Indicator (RSSI) data collected by COTS RFID devices.Data acquisition was performed using a device-free method.Specifically, we design the model based on a Transformer to extract its temporal features.The model uses residualconnected multi-head self-attention to efficiently generate hidden representations while using multiscale convolutional blocks to capture features at different scales to achieve recognition of both single-human activities and HHIs.Experimental results demonstrate the superiority, generality, and efficiency of the TransTM model.Specifically, the TransTM model has a high average recognition accuracy (99.1%) on the actual RFID data, which is 8.0%higher than existing methods.
Our contributions are as follows:
? This paper proposes a novel TransTM model applied to COTS RFID-based device-free HAR.It dramatically improves the recognition accuracy, achieving 99.1% average recognition accuracy,which is 8.0%higher than the state-of-the-art model on average.
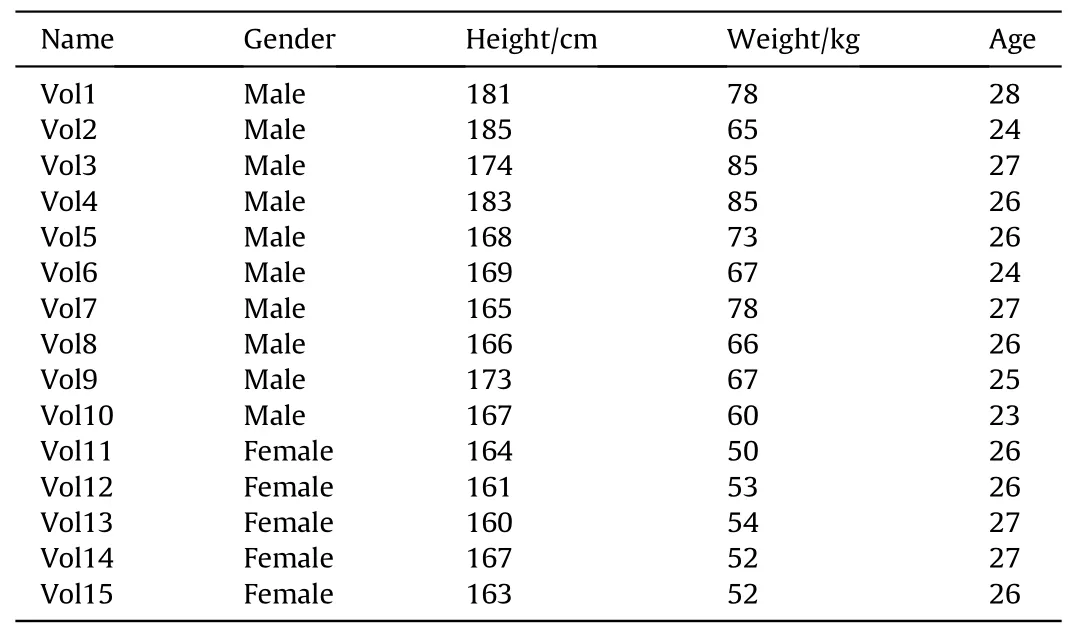
Table 2 The details of the volunteers.
? Our Transformer-based model has great generalization,as it not only takes low-quality data as input, avoiding the hand-crafted data cleaning process but is also valuable for other HAR tasks(e.g., gait and gesture recognition) based on other RF signals such as WiFi, which can be more applicable in practical scenarios.It also precisely recognizes single-human activities and human-human interactions.
? We propose and publish a new RFID dataset with 1.44 million pieces of data containing nine indoor human activities collected based on passive perception.The dataset was collected by the device-free method.
The rest of this paper is organized as follows:Section 2 presents related work on RFID-based HAR and the Transformer.Section 3 details our model.Section 4 presents our dataset, experiments,and results and demonstrates the model’s effectiveness.Finally,we summarize our work in Section 5.

Table 1 Signal pre-processing operations are required for the RF-finger, Tagfree, Dense-LSTM,and TransTM (our model).“?” represents an operation required by the model, and “×” represents operations not required.
2.Relate work
RFID is rising as a promising sensing technology in recent years given its low cost, small size, non-line-of-sight, easy deployment,battery-free,and no maintenance,making it widely used in various applications.Much pioneer research has explored the sensing ability of RFID in activity recognition.
2.1.Traditional schemes for RFID-based activity recognition
Traditional schemes for RFID-based activity recognition first extract discriminative features from multiple domains and then feed the extracted features into machine learning models to predict certain activities as a multiclass classification problem.Wang et al.proposed TACT to hand-crafted extract the intrinsic features of signal reflections in non-contact scenes and then use a segmentation algorithm to identify the stage corresponding to the activity and build a classification model[16].Han et al.proposed a method to use the doppler shift to combine activity sensing, recognition,and counting[17].Shangguan et al.proposed spatiotemporal phase analysis (STPP) by analyzing the temporal and spatial dynamics of phase distribution,computing the spatial order between labels,and using template matching to classify human behavior[18].Yao et al.analyzes the RSSI of the RFID tag array and performs pose classification using support vector machines and linear kernel functions[19].Other popular techniques are support vector machines(SVMs)[20],hidden markov model(HMM)[21],bayesian network[22]and k-nearest neighbor algorithm (KNN) [23].These traditional methods utilize hand-crafted crafted solutions that require export knowledge and are labor-intensive and time-consuming, with the most important problem of hand-crafted extracting fewer representative features of the results.
2.2.Deep learning schemes for RFID-based activity recognition
Subsequently, with the significant improvement of computational power,deep learning has become a very active research field of general activity understanding and has achieved excellent results.Some researchers propose using deep learning methods to extract more fine-grained features automatically.Wang et al.uses a convolutional neural network (CNN) to design the model, and the data requires signal denoising, padding, smoothing, and segmentation before being fed into the network [13].Zhang et al.first preprocessed the data to denoise,smooth, segment,and augment,then designed a model to extract spatiotemporal features from the input data using LSTM [15].Then Fan et al.proposed TagFree to measure the angle of arrival (AoA) of multipath signals using a custom antenna array, denoise and decompose the signal, and input it into a neural network based on a combination of LSTM and CNN [14].Zhao et al.proposed that ExpGRF leverages a complex signal processing pipeline and adversarial learning to extract features for classification[24].Wang et al.proposed that RF-CAR uses adversarial networks for in-vehicle activity recognition[25].These works only recognize the behavior of a single person and require complex data preprocessing before feeding into the classification network.At the same time,the convolution operation is limited by the receptive field, LSTM is easy to overfit, and the adversarial network also has the problem of difficulty in training.
2.3.Transformer
The Transformer has been wildly used in computer vision, natural language processing, and representation learning as its inductive bias can capture the global information of input data.Transformer networks [26,27] is first proposed to represent word embedding vectors and wildly used as the pre-trained model.ViT[28] introduces it to the computer vision field and achieves competitive results with CNN-based methods.Thus, researchers tend to utilize it in many areas,such as image super-resolution[29],image restoration [30], image classification [31,32], image generation [33].As for HAR, the task requires the neural network to be aware of the global signal metric.Therefore,we opt for utilizing the Transformer structure as the backbone, and the experimental results demonstrate the accuracy of our option.
3.Methodology
In this section, we illustrate our Time-streaming Multiscale Transformer (TransTM) model.The model is an end-to-end trainable neural network that uses a multi-scale convolutional hybrid Transformer to capture behavioral features for solving the problem of RFID RSSI-based behavioral classification of individual human activities and HHIs.
We define f as the TransTM model, (a0,a1,.,a79) as the model input, ai?A and "label" as the ground-truth category of the sequence A.We formulated the model objectives as follows:
Fig.2 depicts an overview of our model.It is divided into three parts from left to right:input and pre-processing module,semantic and temporal feature extraction module, and fully connected classification module.
3.1.Input module
The input module receives raw RFID RSSI data and pads it to 140 with 0.We set the sliding window l to 80 and step d to 20 to get the model’s input.To be less memory-intensive,the packaged data was shrunk by undergoing a 4×1 average pooling.
The self-attention operation in Transformer is alignment invariant,ignoring the order of tokens,but the input sequence is an important clue.To make the model order-sensitive,we use learned positional embedding [27] to preserve the location information of RSSI data.
3.2.Semantic and temporal feature extraction module
This module is an H-layer stack of time-streaming multiscale convolutional hybrid Transformers to extract semantic and temporal features of the data.The module consists of two sequentially stacked sub-layers:(1)multi-head self-attention and(2)multiscale residual CNN with adaptive scale attention.Each of these two sublayers contains a residual connection (Add) [34], and a layer normalization (LayerNorm) [35].
We employ a multi-head self-attention mechanism [26] to generate hidden representations from the input, expecting different attention heads to learn different features.Self-attention can globally extract information from the entire sequence,completely solving the long-term dependency problem of RNN and LSTM.Meanwhile, self-attention does not have the problem that the convolution operation in CNN has a limited perception field and needs help handling time-domain information.Moreover, most of the variables in self-attention are calculated internally, so it has a small number of parameters but covers much information per parameter.Self-attention ensures that the initial percentage of each input variable is the same in each calculation, thus ensuring that the attention coefficients obtained after the self-attention layer calculation are plausible.There is also self-attention that can be computed in parallel.

Fig.2.Overview of our TransTM model.The TransTM model has three modules: an input module, a semantic and temporal feature extraction module, and a fully connected classification module.The detailed network hyperparameter settings are marked.
Self-attention outputs a weighted sum of these values.Where the weight assigned to each value is calculated from the queries and the corresponding keys point sum, formally defined as

where Wq?Rdin×dk,Wk?Rdin×dk,and Wv?Rdin×dvare three different transformation matrices.
To extract data features from multiple perspectives and jointly process information from different representation sub-spaces,queries, keys, and values are computed independently c times with different transformation matrices (called c-head), and the obtained results are computed in series with the transformation matrix to obtain the final multi-head self-attention output.
where WM?Rcdv×dMis the final transformation matrix.
In order to facilitate residual connections in multi-head selfattention,all sub-layers and the input share the same size,i.e.din=dM= c× dv.
Since HAR is a sequential task, using only instantaneous extracted features provides insufficient information.Therefore,we use a multiscale residual CNN with adaptive scale attention to extract features from different temporal lengths.It uses convolution kernels of different sizes and adaptively adjusts between scales through an adaptive scale attention mechanism.Moreover,the use of residual connections ensures good information transfer.
Given a set of kernel sizes, G = 〈g1,g2,.,gj〉, each kernel size represents a scale,the features extracted at a particular time point.The output of the convolutional block Z = 〈Z1, Z2,., Zj〉, where Zj?RL×dMis the feature of the j-th kernel size gj.Zjis defined as

where FFN(?) is a fully connected feed-forward neural network.
3.3.Fully connected classification module
The feature Z extracted by the semantic and temporal feature extraction module enters the fully connected classification module and performs two convolutions with kernel sizes of 10×10 and 20× 20, respectively, to further extract information.Furthermore, a 1-max-pooling operation is used to capture the most important features.As shown in Eqs.(9) and (10)

Fig.3.A multiscale convolutional block generates a feature example of semantic and temporal features at position j.The convolution kernel size is 1,3,and 5,and the final features are obtained through adaptive scale attention.

where the Concat operation splice C2at the end of C1generates C,which is provided to the prediction layer to identify different activities.
3.4.Loss function
We use the NLLloss as a loss function to limit our model training.
where label denotes the ground-truth category.L is the loss function.
4.Experimental evaluation
In this section, we evaluate the performance of the proposed TransTM model on the HAR task of collecting COST RFID data through a device-free method and demonstrate that it outperforms state-of-the-art models.
4.1.Our dataset
In our investigation, there are no publicly available RFID-based datasets for the current task.Therefore, we collect and publish 1.44 million pieces of data which contain nine indoor human actions based on passive perception: walk, wave, drink, sit, and call(single-human activities),handshake,give,whisper,and conversate(HHIs).The action schematic is shown in Fig.4.
Experimental Deployment.We use COTS RFID devices to acquire RSSI data using an Impinj R420 reader, connecting 4 Laird 9028 antennas and 35 ImpinJ H47 Tags.Then we fixed labels in 5×7 with a spacing of 0.3 m and attached them to the wall where the fifth row of labels is 0.5 m above the ground.At a distance of 3.0 m from the tag wall,we place four antennas and allow the antenna array to communicate with the RFID tag wall in a polling mode.The volunteers stand anywhere between the RFID tag wall and the antenna array and perform nine actions.RFID RSSI data acquisition experiment scenario is shown in Fig.5.
To ensure the generality and authenticity of the collected data,we have 15 volunteers,including ten males,and five females,with a height range of 160-185 cm, a weight range of 50-85 kg, and an age range of 23-28.Table 2 shows the details of the volunteers.The specific amount of data is shown in Table 3.It can be seen that our data is balanced.
To make the experimental environment more suitable for the daily environment,we set up an experimental scene in the activity room with an area of approximately 6.5 m×10.5 m.Besides,during the data collection process,we place other interference factors such as office work, green plants, table tennis tables, and sundries.The actual experimental environment is shown in Fig.6.

4.2.Experimental settings and evaluation metrics
Experimental Settings.The model is implemented using Pytorch 1.5.0 with Python 3.7 and trained on an NVIDIA Tesla K80 GPU.For optimization,we use Adam with a learning rate of 0.001.We utilize 5-fold cross-validation, randomly split the dataset into five parts,select one part for verification each time,and use the remaining data for training,a total of five training times.During the training,we set the batch size to 16 and trained 50 epochs.The dropout rate is 0.1.The detailed network hyperparameter settings are shown in Fig.2.
Evaluation Metrics.In order to comprehensively evaluate the proposed method, we adopt four different evaluation metrics,including recognition accuracy (i.e., the proportion of correctly recognized activities among all predictions), F1-score (i.e., the harmonic mean of precision and recall),FLOPs, and parameters.

Fig.4.Action classification diagram.Where walk, wave, drink, sit, and call are single-human activities, and handshake, give, whisper, and conversate are HHIs.

Fig.5.RSSI data acquisition experiment scenario.Volunteers stood anywhere between the RFID tag wall and the antenna array, performing nine actions, and there was environmental noise: (a) The actual data acquisition scenario; (b) The schematic diagram of the experimental acquisition scenario.

Table 3 The amount of data.
Baseline.We compare four state-of-the-art models based on deep learning: two CNN-based models RF-finger [13] and LiteHAR[36], and two LSTM-based models Tagfree [14] and Dense-LSTM[15].These four models solve the RF-based HAR task through the device-free method and utilize the usual deep learning method,so these four models are selected as the baseline.
4.3.Performance of our TransTM
It can be visualized from Fig.7 that the TransTM model achieves excellent results.The abscissa is the classification result predicted by the model, and the ordinate is the ground-truth category.The confusion matrix is diagonally distributed.
Comparing the TransTM model with baselines, the results are shown in Tables 4 and 5.As can be seen,the TransTM achieves the highest average accuracy and F1-score and significantly outperforms all baselines in classification accuracy across all classes,achieving the state-of-the-art result on our experimental data.The average classification accuracy of the TransTM model is 13.7%,6.3%,4.0%,and 81.8%higher than that of RF-finger,Tagfree,Dense-LSTM,and LiteHAR,respectively.Meanwhile,the F1-score of our TransTM is also 15.5%, 7.3%, 4.1%, and 98.2% higher than that of RF-finger,Tagfree, Dense-LSTM, and LiteHAR, respectively.This shows that our time-streaming multiscale convolutional hybrid Transformer structure achieves better performance in the HAR task.

Fig.6.The environment of the activity room.
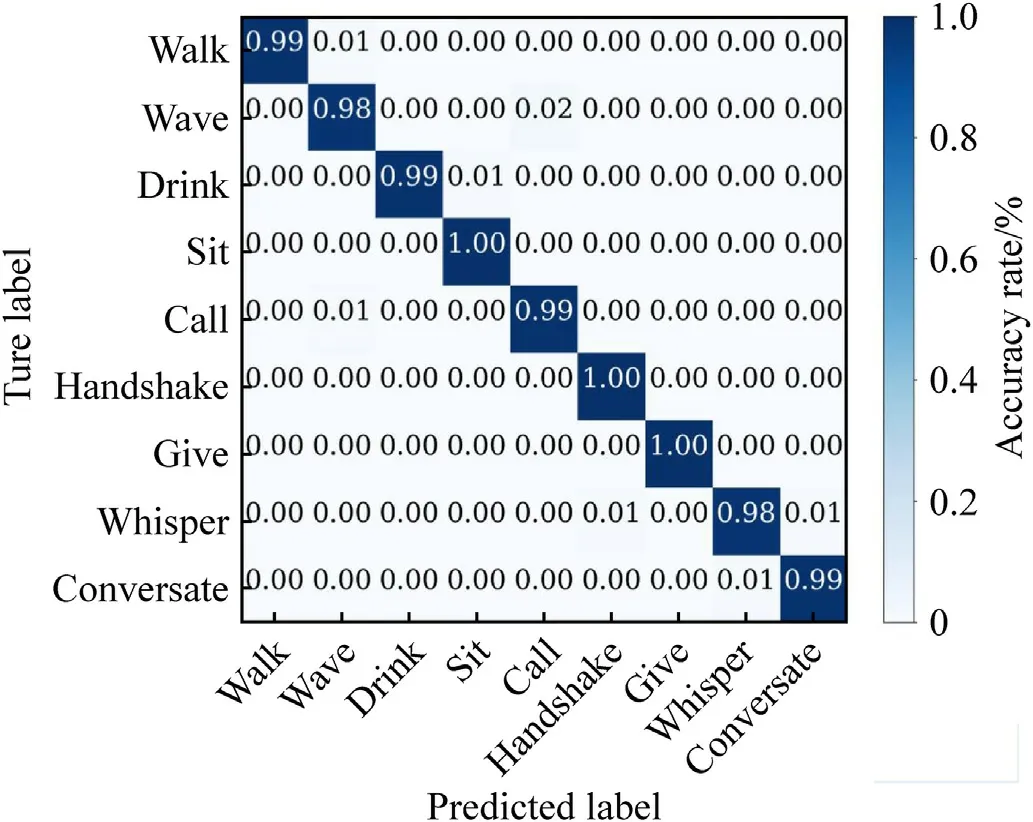
Fig.7.Confusion matrix visualization.
Fig.8(a) shows the loss curves (lg) of TransTM, RF-finger, Tagfree, and Dense-LSTM models trained on our experimental data,while Fig.8(b)shows the loss curves(lg)of LiteHAR.The loss curve of TransTM fits perfectly and has the best degree of convergence.

Table 4 Performance comparison with baselines.TransTM is our model.
We conduct further experiments to demonstrate the superiority and generality of our TransTM model.Due to the lack of publicly available datasets for RFID-based HAR tasks, we evaluate three WiFi-based public datasets:Office Room4[40],Widar3.0_Gait[41],and Widar3.0_Gesture[42]which are the coarse-grained HAR task,the coarse-grained personnel identification task based on collected gait WiFi data, and the fine-grained gesture recognition task respectively.All three datasets are device-free methods.The experimental results are shown in Table 6.Our TransTM model,designed based on Transformer, has satisfactory average accuracy on the three datasets,which is attributed to the robust data fitting capability of the Transformer model.Although it is much more challenging to recognize fine-grained HAR tasks than coarsegrained ones, resulting in slightly lower accuracy of our TransTM model on Widar3.0_Gesture, it also achieves a 93.3% accuracy.Moreover, for these three tasks, the average accuracy of existing methods is 90% [37], 95% [38], and 94% [39], respectively, which proves that our TransTM model can solve a variety of human behavior classification problems based on RF signals.
To verify the time efficiency of the model, we present the empirical execution time on our experimental data in Table 7.As seen from the table, the TransTM model takes second place, only using 10.43 ms to infer each record,so the time cost of the model can be ignored.This shows that our model is practical and sufficient for RFID-based real-time human activity recognition.Furthermore, the time required to process data on the CPU device is only 17 ms.Therefore, the inference cost of our TransTM model is friendly in practice.
4.4.Analyses

Fig.8.The loss curve of the comparative experiment: (a) Loss curves (lg) for RF-finger, Tagfree, Dense-LSTM and TransTM (our model); (b) Loss curve for LiteHAR.

Table 5 Comparison of classification accuracy(%).TransTM is our model.

Table 6 The average recognition accuracy(%)of the TransTM model on the three evaluation datasets.

Table 7 Test calculation processing time comparison.TransTM is our model.
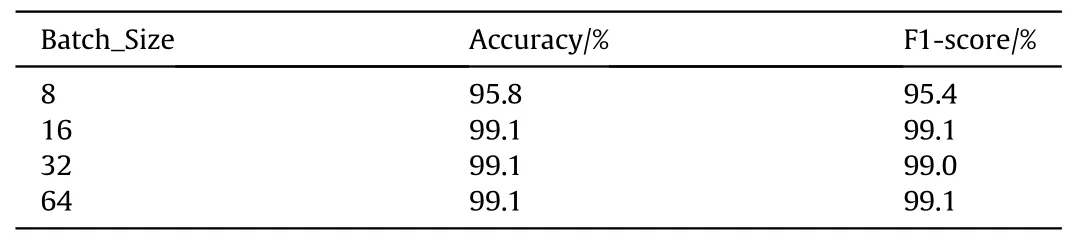
Table 8 The effect of batch size on model performance.We set the batch size to 16.
The HAR task is to judge the relative position changes of the volunteers’ limbs and torso over a while, thereby recognizing the action.This time sequence is essential.To better utilize the order of the input sequence, the model adds the learned position to each token in the input sequence.Beyond that, the self-attention mechanism captures long-distance information and dynamically adjusts the perceptual field according to the content.Therefore,our TransTM model is the best in both the average classification accuracy and the recognition of each class.The multi-head self-attention module and all convolution modules can be computed in parallel, so our TransTM model is faster than Tagfree and Dense-LSTM in test processing.Since our TransTM model is much more complex than the RF-finger model,the time is slightly longer.While the LiteHAR model pursues lightweight,the model is the simplest,so the time is the shortest, but its performance is also the worst.
From Tables 4 and 5, we can find that the performance of the LiteHAR model is the worst.This is because the LiteHAR model uses the simplest CNN to build the feature extractor of the model in order to pursue lightweight,so the feature extraction ability of the model cannot meet the needs of complex scenes.The RF-finger model, with a single frame as the model input, lacks temporal features compared with our TransTM model, and the model performance is slightly unsatisfactory.The reason is that the extraction of time series features plays a crucial role in model performance.The Tagfree model introduces unidirectional LSTM, and Dense-LSTM introduces bidirectional LSTM.Due to the shortcomings of LSTM itself,its training process is unstable,and the loss is difficult to suppress, which also causes Tagfree and Dense-LSTM to be less effective than our TransTM model.
4.5.Ablation experiment
We evaluate the selected hyperparameters through ablation experiments,including the contribution of residual structure in the proposed multiscale residual CNN,the effect of the size of the input sliding window on the model performance,batch size,the number of layers H of the time-streaming multiscale convolutional hybrid Transformers and the number of heads c of multi-head selfattention.
As can be seen from Fig.9,the TransTM model of multiscale CNN with residual structure performs better, especially in the call category, the accuracy rate is 14% higher.The residual structure improves the correlation between the gradient and the loss,thereby improving the network’s learning ability and solving the degradation problem,which is still vital for training networks with fewer layers.
Due to the uncertainty of the action duration, the sliding window size of the input data needs to be discussed.In Fig.10,we can see that the model becomes better as the sliding window gets larger since more information is available to the network.When the sliding window size is 80,the classification rate of the model is high and more stable than the size of 100,so the sliding window size of the model is 80.
According to Table 8,when the batch is 16,the model’s accuracy is 99.1%,and the F1-score is 99.1%.A larger batch will not improve the model’s performance, so we set the batch to 16.
It can be seen from Table 9 that as the number of layers H of the time-streaming multiscale convolutional hybrid Transformers increases, the model’s performance improves.When H is 5, the performance of the model is the best.
In Table 10, the more heads c of multi-head self-attention, the higher the correct rate of the model, but the more FLOPs and parameters of the model.When c is 4,the model’s performance is the best overall.
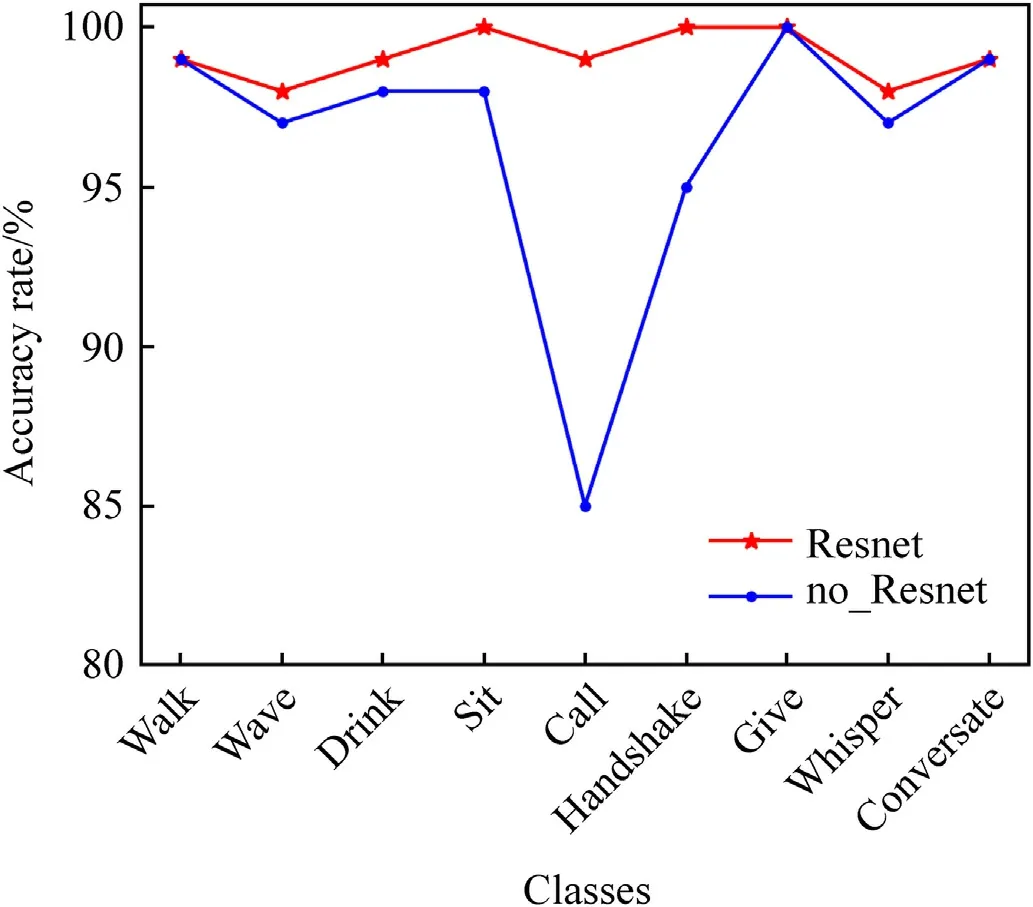
Fig.9.Line graph of the ablation experiment results of residual structure in multiscale residual CNN.

Fig.10.Line graph of the ablation experiment results of the size of the input sliding window.

Table 9 The effect of the number of layers H of the time-streaming multiscale convolutional hybrid Transformers on model performance.We set the H to 5.

Table 10 The effect of the number of heads c of multi-head self-attention on model performance.We set the c to 5.
5.Conclusions
In this paper,we propose a novel neural network, TransTM,for the HAR task of collecting RFID data through the device-free method.Our method achieves powerful data fitting capabilities to take raw RFID RSSI data as input and avoid data pre-processing.Furthermore, we propose a multiscale convolutional hybrid Transformer to capture behavioral features that recognize singlehuman activities and human-to-human interactions.Comparison experiments on our proposed RFID-based datasets show that our method achieves the highest average recognition accuracy(99.1%),outperforming the state-of-the-art models.Moreover,experiments on public RF signal-based datasets for the coarse-grained HAR task,the personnel identification task, and the fine-grained gesture recognition task demonstrate the generality of our method.Ablation experiments show that the hyperparameter settings are satisfactory.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
The author would like to acknowledge the support provided by the Strategic Priority Research Program of Chinese Academy of Sciences (Grant No.XDC02040300) for this study.

- Defence Technology的其它文章
- Ground threat prediction-based path planning of unmanned autonomous helicopter using hybrid enhanced artificial bee colony algorithm
- Layered metastructure containing freely-designed local resonators for wave attenuation
- Predicting impact strength of perforated targets using artificial neural networks trained on FEM-generated datasets
- Construct a 3D microsphere of HMX/B/Al/PTFE to obtain the high energy and combustion reactivity
- Ignition processes and characteristics of charring conductive polymers with a cavity geometry in precombustion chamber for applications in micro/nano satellite hybrid rocket motors
- Recent research in mechanical properties of geopolymer-based ultrahigh-performance concrete: A review